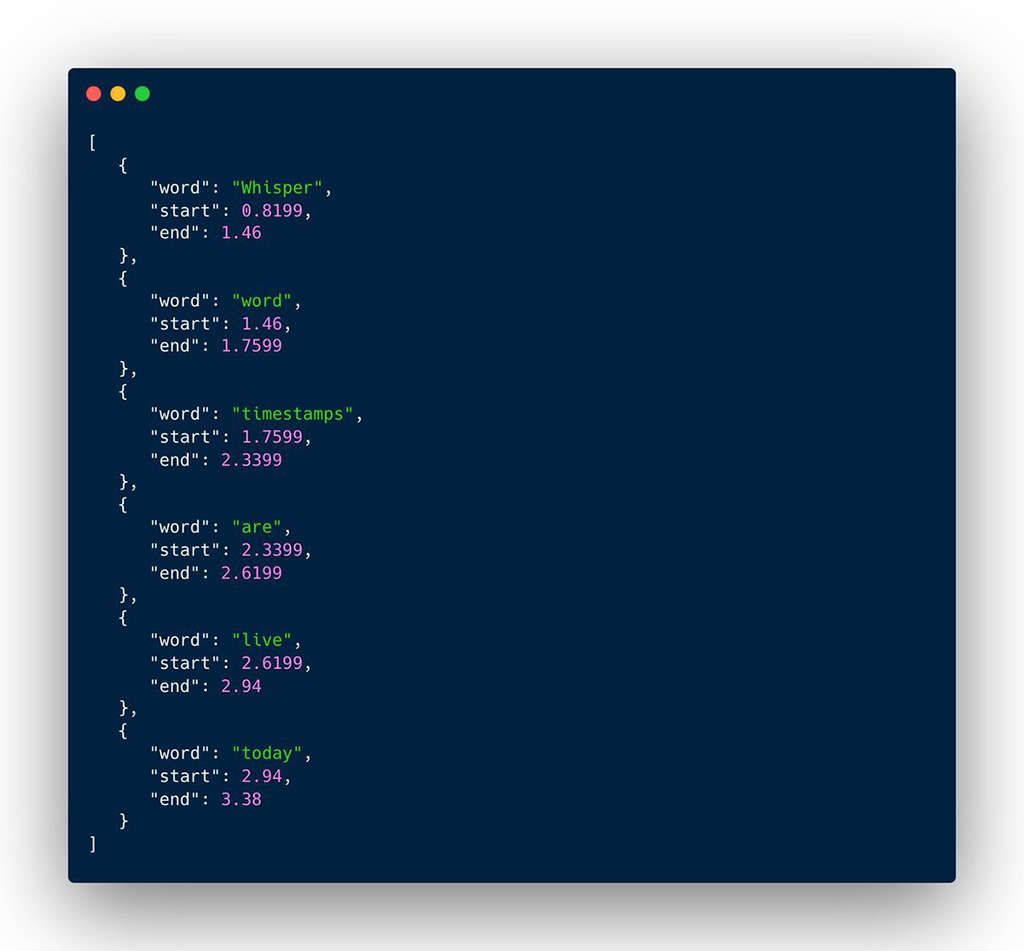
Scraperr 是一款自架(self‑hosted)的網頁爬蟲工具,由 GitHub 使用者 jaypyles 開發,由前端(Next.js + TailwindCSS)與後端(FastAPI + Python)分工,搭配 MongoDB 支援,讓使用者可以透過圖形介面與設定,就能進行網頁資料擷取,完全免寫程式碼。
核心特色
-
XPath 定位: 使用 XPath 精準擷取網頁元素,不需編寫程式語法 。
-
任務佇列管理: 能夠一次送出多個 URL、查看任務狀態、結果匯出。
-
全域爬取支援: 可選擇巢狀 Domain 抓取功能,也就是自動掃描相同網域的多個頁面。
-
自訂 HTTP Headers: 支援輸入額外 JSON 格式標頭,像是 Cookie、User-Agent 。
-
媒體下載: 自動抓取圖片、影片、檔案等媒體內容。
-
視覺化結果: 結果以表格方式呈現,並能匯出成 Markdown 或 CSV 格式 。
-
通知機制: 支援任務完成通知,可整合各種渠道通知使用者 。
Scraperr 做為一個完整的 self‑hosted 爬蟲平台,整合了前後端分離設計、圖形化操作、擴充性好與媒體下載等功能,不論是初學者快速上手或進階使用都相當適合。












![[Flask 教學] 在 Jinja2 樣板使用 HTML 標籤](/assets/upload/1664330673271_0.png)