OpenAI推出了一項基於Whisper模型的聲音轉文字API,能夠將任何聲音檔案直接轉寫成文字並翻譯成英文。
同時,在轉寫文字的過程中,API能提供每個詞彙或句子出現的確切時間點,協助使用者精準定位聲音檔案中的特定內容。
主要功能包括:
1、聲音轉文字:自動將聲音檔案內的語音內容轉換為文字,讓使用者能夠閱讀到聲音檔案中的談話內容。
2、支援多語言翻譯轉寫:若聲音檔案中的語言非英語,該API還能先將之翻譯成英語,再進行轉寫,使得非英語內容也能輕鬆轉換為文字。
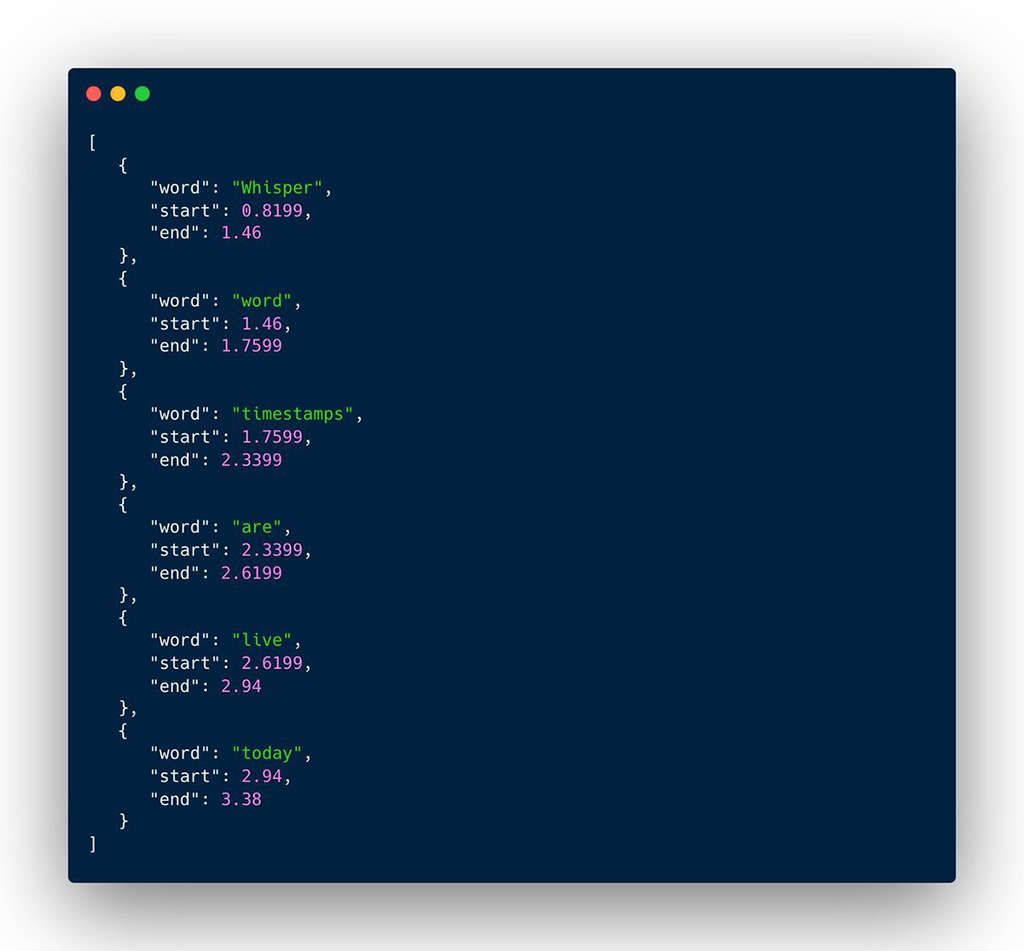
3、提供時間戳記:OpenAI的Whisper API提供了一個選項timestamp_granularities[],允許使用者獲取帶有時間戳記的更結構化的JSON輸出格式。這表示,在轉寫文字的同時,API能提供每個詞彙或句子出現的確切時間點,幫助使用者精準定位聲音檔案中的特定部分。
4、支援多種聲音檔案格式:支援上傳25MB以內的檔案,包括mp3、mp4、mpeg、mpga、m4a、wav和webm等格式。使用者無需轉換檔案格式即可直接使用。