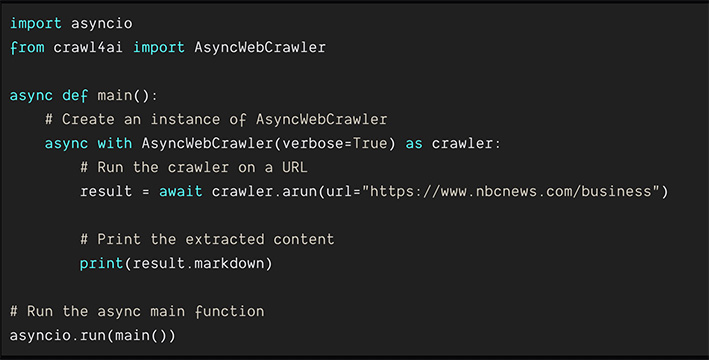
Crawl4AI 是由開發者 unclecode 推出的一個開源專案,專注於網頁資料的自動化抓取和處理,特別適合用於人工智慧(AI)和機器學習(ML)模型的數據訓練。該工具透過自動化的網頁爬蟲技術,幫助用戶快速蒐集大量的網路資料,提供資料標註與清理的功能,進而加速 AI 訓練資料的準備過程。
Crawl4AI 的主要功能
-
自動化網頁爬取
- Crawl4AI 支援自動化的網頁爬取,能夠快速抓取大量的網頁資料。透過設定網頁 URL 或關鍵字,它可以自動蒐集符合條件的網頁內容,適合用來建立各種應用場景下的數據集,如自然語言處理(NLP)、圖片分類或語音辨識等。
-
多種資料格式支援
- 該工具支援從網頁抓取的多種資料格式,包括文字、圖片、影音等。這意味著用戶可以根據需求蒐集不同類型的資料,為 AI 訓練提供多元的數據來源。此外,Crawl4AI 也支援將資料轉換成常見的 JSON、CSV 等格式,方便後續資料處理和分析。
-
資料清理與標註功能
- 在抓取資料的過程中,Crawl4AI 提供了基本的資料清理功能,如去除重複資料、過濾不必要的 HTML 標籤等。更進一步,該工具還支援資料標註,讓用戶能夠快速對蒐集的資料進行分類和標籤化處理,這對於有監督學習的模型訓練非常重要。
-
支援反爬蟲技術的應對
- 許多網站都有反爬蟲機制,Crawl4AI 具備隨機 User-Agent、IP 代理、時間延遲等技術,來應對各種反爬蟲措施。這使得用戶可以更順利地進行網頁資料的抓取,並減少因為爬蟲活動被封鎖的風險。
-
開源且可擴展
- 作為一個開源工具,Crawl4AI 的原始碼完全公開,開發者可以根據特定需求來修改或擴展其功能,將其整合至現有的工作流程中,或針對不同領域的應用進行優化。
Crawl4AI 的潛在應用
-
自然語言處理(NLP)數據集建立
- 對於從事 NLP 研究或開發的工程師,Crawl4AI 可以自動蒐集大量的文字資料,像是文章、評論、論壇討論等,為語言模型提供訓練素材。
-
圖像識別和分類
- 透過 Crawl4AI 自動下載網頁上的圖片資料,能夠快速建立圖像分類所需的訓練集。搭配圖片標註功能,可以輕鬆準備有標籤的圖片資料集。
-
情感分析和市場調查
- 利用 Crawl4AI 抓取社群媒體上的評論或論壇上的討論串,能夠快速蒐集大量的用戶回饋資料,有助於情感分析、產品評價研究或市場趨勢預測。
-
學術研究與知識探索
- 對於學術研究者來說,Crawl4AI 可以自動化地抓取學術資料庫或網路上的論文資料,快速建立研究所需的文獻資料集。
Crawl4AI 是一個針對人工智慧訓練數據準備所設計的強大網頁資料爬蟲工具。它自動化的流程、大量資料格式支援及開源的彈性,使其成為各種 AI 應用數據準備的理想選擇。對於有資料蒐集需求的開發者或研究者來說,Crawl4AI 無疑是一個值得推薦的解決方案。通過適當的設定和應對策略,能夠大幅提升資料收集的效率,加速 AI 模型訓練的進程。