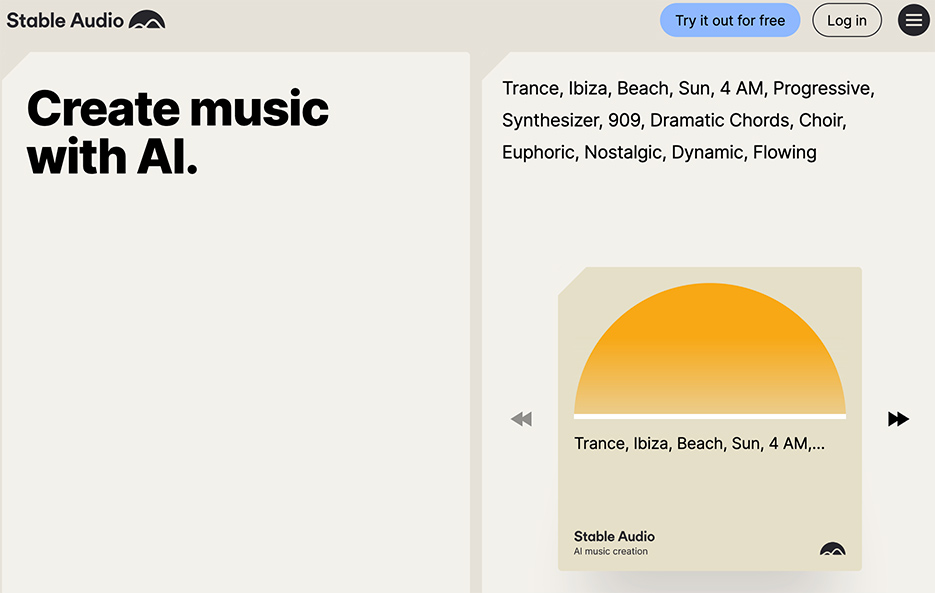
Stable Audio是Stability AI的第一個用於音樂和音效生成的產品。使用者可以通過輸入prompt和時間來生成原創音樂,生成高品質的44.1 kHz立體聲音樂。它使用了一種潛在擴散聲音模型,該模型是通過來自AudioSparx的數據訓練而成。
借助最新的擴散取樣技術,Stable Audio 模型在 Nvidia A100 GPU 上以 44.1 kHz 的取樣速度,不到 1 秒就能渲染出 95 秒的立體聲音樂。
使用方法跟一般圖像生成的一樣,只要輸入 prompt 就好了

生成後就可以下載:
這裡有一個我搭配 ChatGPT 生成的 promt 的介紹影片:
Stable Audio 同時提供免費與 Pro 付費版,前者每月可免費生成 20 次、最長 45 秒的聲音或音樂,而若每月支付 12 美元,則可生成 500 次、最長 90 秒的音樂。
另外也可以聽看看我之前生成的音樂。