Meta(前 Facebook)最新推出的 SAM Audio,是一款用於音訊分離與音訊編輯的人工智慧模型,它代表了目前音訊處理領域的一大突破,可讓人類用比以往更直覺、更方便的方式來「剖析」聲音內容。
這個模型採用 Meta 先前在 Segment Anything 視覺領域中開發的技術(例如 SAM 物件分割技術)為基礎,再延伸到音訊領域,使得音訊處理也能有類似圖像上的「可點選、可描述、可操作」特性。
SAM Audio 的核心能力與特色
多模態提示(Multimodal Prompts)
SAM Audio 的最大特色在於它支援三種提示方式,讓模型可以從複雜的音訊混合中分離出特定聲音:
-
文字提示(Text Prompt):輸入「吉他」「人聲」「噪音」等描述來指定要提取的聲源。
-
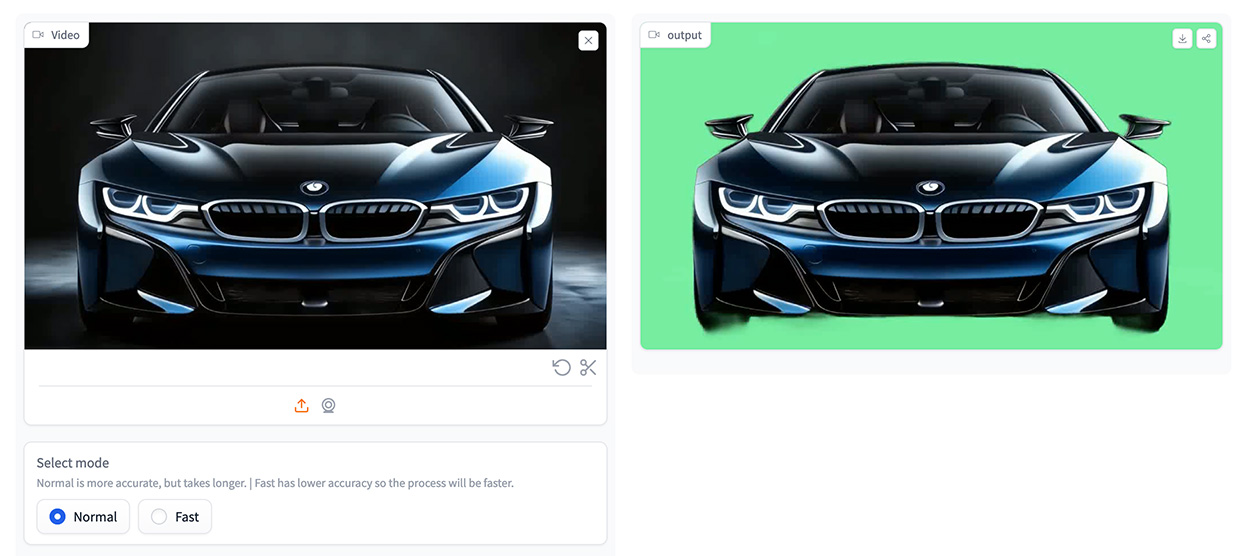
視覺提示(Visual Prompt):即使是從影片中,點選畫面上的人物或樂器也能指定相對應的聲音來源。
-
時間區段提示(Temporal/Span Prompt):圈選時間段來分離該段聲音。
這種設計模擬了人類處理聲音的自然方式,不再需要複雜的手動剪輯流程。
技術基礎:「感知編碼器視聽(PE-AV)」
SAM Audio 的核心架構名為 PE-AV(Perception Encoder Audio-Visual),它是一種融合視覺與音訊理解能力的感知編碼器,能夠同時處理文字、圖像與時間訊息,達成更加穩健與精準的音訊分離與定位。
可能的實際應用場景
SAM Audio 的應用範圍十分廣泛,包含但不限於:
-
音樂與混音分離:從混合音樂中提取吉他、鼓、主唱、人聲和各種樂器單獨聲軌。
-
錄音淨化與降噪:移除背景噪音(如交通噪音、狗叫聲、風聲)以提高錄音清晰度。
-
影音編輯:從影片中選擇人物或物件即刻抽取對應音效。
-
Podcast 內容處理:快速去掉雜音或突出主講者聲音。
-
科學研究與無障礙應用:例如助聽裝置與語音分析任務。
總結
SAM Audio 是 Meta 將多模態 AI 技術從視覺分割延伸到音訊領域的重要成果,結合語義理解、視覺提示與時間提示三大交互方式,使音訊分離與編輯變得更直覺與強大。這代表著 AI 在音訊處理上的新階段,可應用於音樂製作、影音編輯、Podcast後製等多種創作與分析場景,是現階段音訊創作者與技術人員不容忽視的新工具。