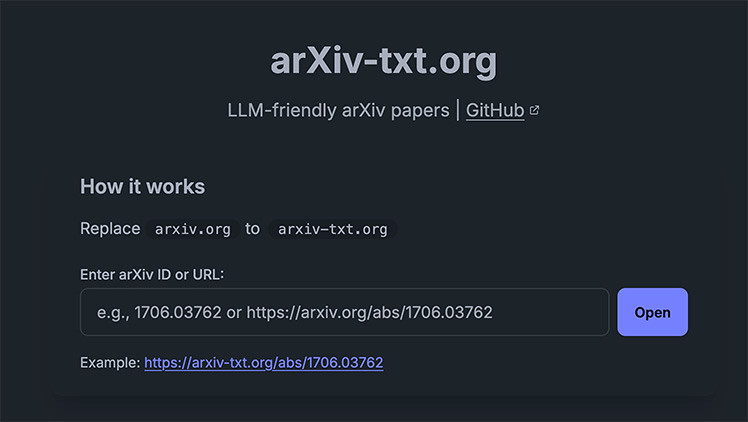
在學術研究領域,arXiv 是一個廣為人知的預印本資料庫,收錄了大量物理學、數學、計算機科學等領域的論文。 然而,這些論文的格式和結構可能對大型語言模型(LLM)的處理造成困難。為了解決這一問題,arXiv-txt.org 應運而生,提供了一個將 arXiv 論文轉換為 LLM 友好格式的平台,方便研究人員和開發者進行進一步的分析和應用。
arXiv-txt.org 的主要功能與特色
1. 簡單的 URL 替換,快速獲取純文字內容
使用 arXiv-txt.org,您只需將原始 arXiv 論文的 URL 中的 arxiv.org 替換為 arxiv-txt.org,即可獲取該論文的純文字版本。例如,將 https://arxiv.org/abs/1706.03762 替換為 https://arxiv-txt.org/abs/1706.03762,即可訪問該論文的 LLM 友好格式。
2. 提供 API,方便程式化存取
arXiv-txt.org 設計了易於使用的 API,允許開發者程式化地獲取論文的摘要或全文內容。例如,通過訪問 https://arxiv-txt.org/raw/abs/[id] 可以獲取論文的摘要,訪問 https://arxiv-txt.org/raw/pdf/[id] 則可獲取全文內容。這使得開發者能夠輕鬆地將 arXiv 論文整合到他們的應用程式中。
3. 多種程式語言支援,靈活的開發體驗
無論您使用 Python 還是命令列工具,arXiv-txt.org 都提供了相應的使用範例。例如,在 Python 中,您可以使用 requests 庫來獲取論文的純文字內容,並將其傳遞給您的 LLM 進行處理。在命令列中,您可以使用 curl 命令直接將論文內容輸出到檔案或其他應用程式。
arXiv-txt.org 極大地簡化了從 arXiv 獲取論文純文字的流程。傳統上,從 PDF 中提取文字可能會遇到格式混亂等問題,而通過 arXiv-txt.org,您可以直接獲取結構清晰的純文字,方便 LLM 的解析和理解。這對於需要批量處理大量論文的研究人員和開發者而言,無疑是一個高效的解決方案。
總而言之,arXiv-txt.org 為需要將 arXiv 論文與大型語言模型結合的使用者提供了一個便捷且高效的工具,值得在相關領域中推廣使用。