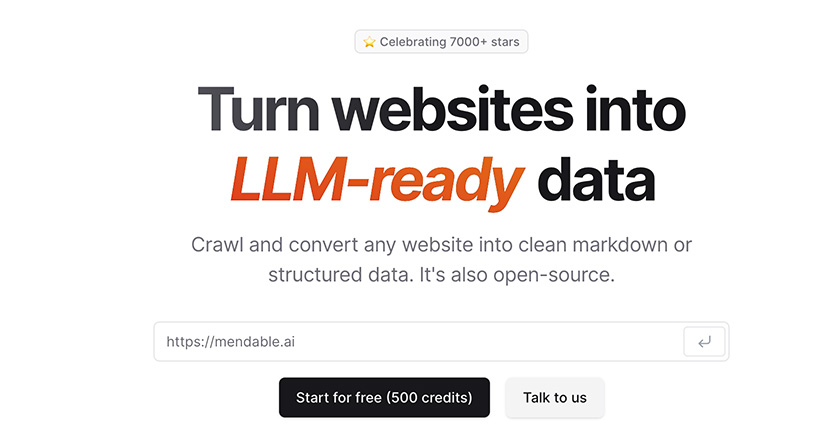
Firecrawl 是一個專為 AI 應用與大型語言模型(LLM)打造的網頁擷取平台,核心用途是將網站內容轉換成 AI 容易理解與處理的格式。相較於傳統爬蟲工具專注於資料收集,Firecrawl 更聚焦於「讓 AI 能夠直接使用網站資訊」,因此在近年 RAG(Retrieval-Augmented Generation)、AI Agent 與知識庫建置領域獲得相當高的關注。
許多開發者在建立 AI 助理、企業知識庫或 Agent 系統時,經常會遇到一個問題:網站內容雖然公開存在,但 HTML 結構複雜、廣告與導覽元素眾多,直接丟給大型語言模型不僅浪費 Token,也容易影響回答品質。Firecrawl 的定位正是解決這個問題,它會自動爬取網站、解析內容、移除雜訊,並輸出乾淨的 Markdown 或結構化資料,讓 AI 能夠直接使用。
從產品定位來看,Firecrawl 並不是傳統 SEO 爬蟲,也不是資料採集工具,而是一個 AI-Ready Web Data Platform。官方主打的概念相當明確:
Crawl any website and turn it into clean data for AI.
這意味著 Firecrawl 的目標不是收集越多資料越好,而是讓收集到的內容更適合大型語言模型與 Agent 系統使用。
從功能層面來看,Firecrawl 提供的能力相當完整,包括:
- 單頁網頁擷取(Scrape)
- 整站爬取(Crawl)
- 網站地圖探索(Map)
- 搜尋引擎整合(Search)
- Markdown 轉換
- JSON 結構化輸出
- JavaScript 網站支援
- 動態內容渲染
- AI Agent 整合
- RAG 知識庫建置
這些功能讓 Firecrawl 不只是抓取網頁,而是從資料擷取一路延伸到 AI 應用準備階段。
從實際使用情境來看,Firecrawl 特別適合建構 AI 知識庫。
例如企業希望建立:
- 客服聊天機器人
- 產品問答系統
- 內部知識搜尋
- 文件查詢 Agent
傳統流程需要:
- 網頁爬取
- HTML 清理
- 文字轉換
- Chunking
- Embedding
而 Firecrawl 可以一次完成前面多個步驟,大幅簡化工作流程。
另一個值得注意的特色,是其對現代網站的支援能力。
許多傳統爬蟲工具在面對:
- React
- Vue
- Next.js
- Nuxt
- SPA(Single Page Application)
時容易失效。
Firecrawl 則內建瀏覽器渲染能力,能處理 JavaScript 動態產生的內容,因此對現代前端網站有較好的相容性。
從開發者角度來看,Firecrawl 最大的優勢之一是 API 設計相當簡潔。
例如只需要提供網址,即可取得整理後的內容。
這種設計降低了 AI 開發門檻,也讓許多 Agent Framework 能快速整合。
目前 Firecrawl 已被廣泛應用於:
- AI Agent
- RAG 系統
- LangChain 工作流
- LlamaIndex 專案
- 客服機器人
- 市場研究工具
- 文件搜尋系統
等場景。
從技術架構來看,Firecrawl 本質上是一個 Web Data Infrastructure。它不只提供 SaaS 服務,也支援開源版本與自行部署,讓企業能將資料處理流程保留在自己的環境中。
這種模式對重視隱私與資料安全的組織相當有吸引力,特別是在金融、法律、醫療與企業知識管理等領域。
整體而言,Firecrawl 是目前 AI 開發領域最具代表性的網站擷取平台之一。它將傳統爬蟲、內容清理與 AI 資料準備流程整合成單一服務,讓開發者能更專注於建立 Agent、RAG 與智慧搜尋功能,而不必花費大量時間處理雜亂的網頁資料。隨著 AI 應用對高品質資料需求持續增加,Firecrawl 已逐漸成為許多 AI 團隊基礎工具鏈中的重要一環。