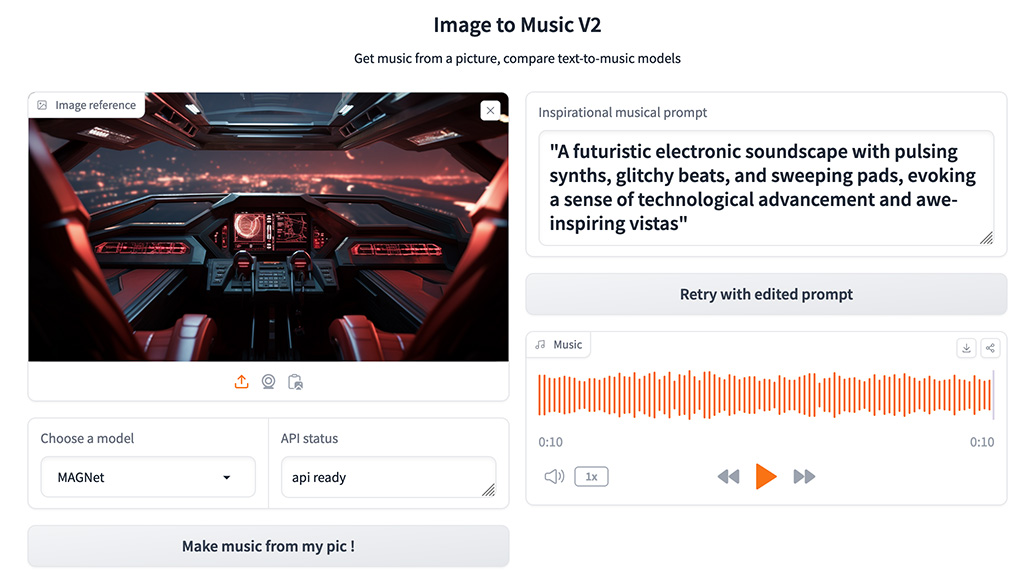
Image to Music V2 是一個可以藉由 AI 透過圖片生成音樂的服務,上傳照片後,系統將分析您的圖像,並以文字形式描述它所見的內容,彷彿為圖片編織一段簡短的故事。
隨後,這段文字描述會轉交給一個語言模型代理,轉化為音樂模型能夠理解的啟發性提示。
最終,這些提示會用於生成與主題相符的特定音樂。
以下是我就由這個服務生出來的音樂範例:
主要步驟概述如下:
Image to Music涵蓋了人工智慧多個領域的結合,包括圖像辨識、自然語言處理以及音樂創作。整個過程大致可分為以下幾個階段:
1、圖像辨識:系統首先運用圖像辨識模型(例如Microsoft的Kosmos-2-patch14-224)來分析用戶上傳的圖片。該模型能夠識別圖片中的物件、場景及可能的情感,並基於這些信息生成一段文字描述,這段描述力求忠實反映圖片的內容。
2、自然語言處理(NLP):接著,將這段文字描述送給一個大型語言模型(如HuggingFace的Zephyr-7b-beta)處理。此階段的目的是將圖像的文字描述轉換成音樂創作的啟發性提示。該語言模型會解讀圖片描述中的內容與情感,並基於此產生一條指引音樂創作的指令,旨在啟發音樂生成模型創作出與圖片內容相匹配的音樂。
3、音樂創作:最後,根據語言模型提供的音樂創作提示,選擇一個音樂生成模型(如MAGNet、MusicGen、AudioLDM-2、Riffusion或Mustango)來創作音樂。這些音樂生成模型會依據啟發性提示來創作出旋律、和聲或是完整的音樂作品,具體取決於模型的設計與能力。
4、用戶自定義:系統允許用戶根據個人偏好和創作需求,調整啟發性提示並選擇不同的音樂生成模型,以提供個性化的音樂創作體驗。用戶可依據自己的喜好調整啟發性提示,並選擇不同的音樂生成模型,以實現多樣的音樂風格與效果。