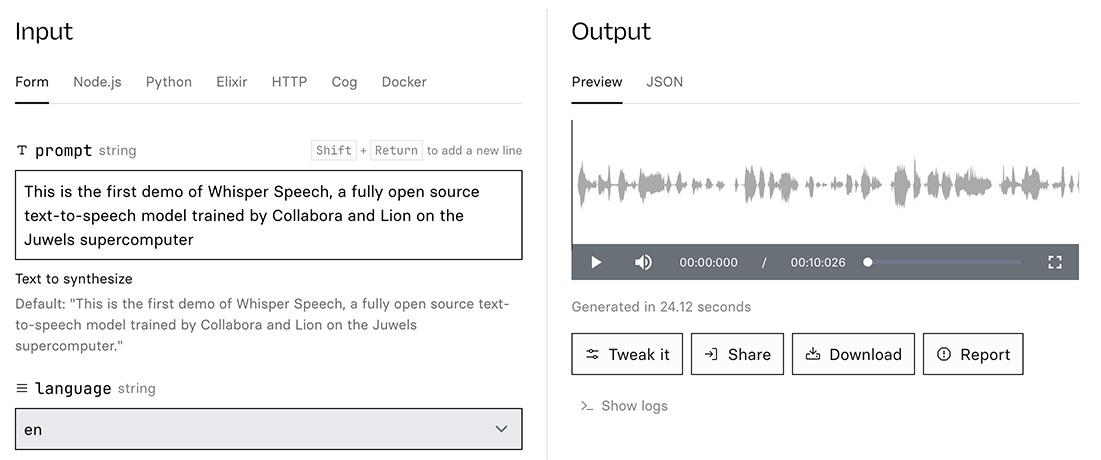
該系統透過對OpenAI的Whisper語音識別模型進行逆向工程來實現。
經由這種逆向過程,WhisperSpeech能夠接受文字輸入,並利用經過改良的Whisper模型產生聽起來自然的語音輸出。
輸出的語音在發音準確度與自然度上均表現出色。
WhisperSpeech 項目的路線圖:
- 聲學標記提取:改善聲學標記的提取過程。
- 語義標記提取:利用Whisper模型生成並量化語義標記。
- S->A 模型轉換:開發將語義標記轉換為聲學標記的模型。
- T->S 模型轉換:實現從文字標記到語義標記的轉換。
- 提升EnCodec語音品質:優化EnCodec模型以提高語音合成品質。
- 短句推理優化:增強系統處理短句的能力。
- 擴展情感語音資料集:收集更大規模的情感語音數據。
- 文件化LibriLight資料集:在HuggingFace上詳細記錄資料集。
- 多語言語音收集:集結社群資源,收集多種語言的語音。
- 訓練多語言模型:開發支援多種語言的文字轉語音模型。