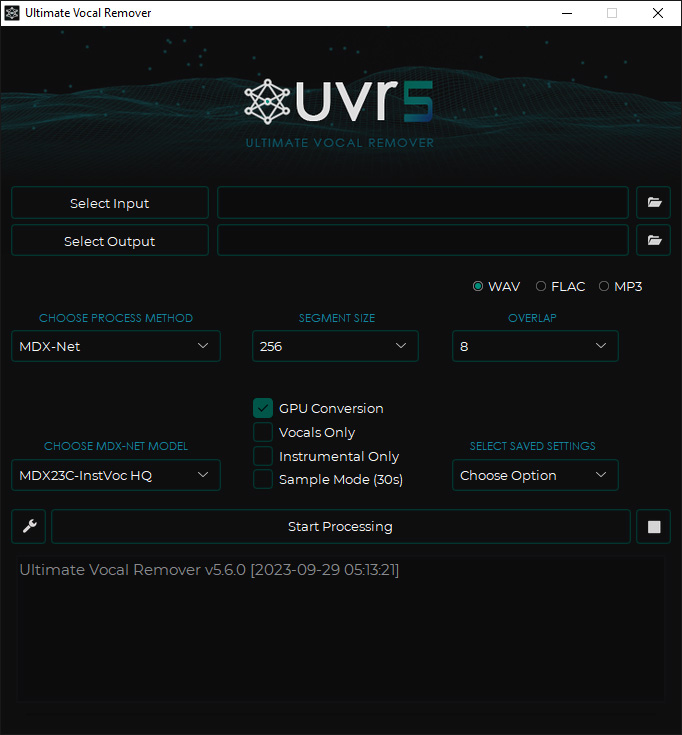
在處理音樂或影音作品時,很多人常常會遇到需要「去人聲」或「分離伴奏」的需求。無論是想自製卡拉 OK 伴奏、為影片配樂,或者是進行混音、翻唱,Ultimate Vocal Remover GUI(UVR) 這個工具就是用來提供簡單又強大的解決方案。這款免費的開源工具,透過直覺的圖形化介面,讓使用者輕鬆把歌曲中的人聲、樂器或背景音效分開,並支援多種不同的分離模式。更棒的是,它同時支援 Windows、macOS 與 Linux,用戶只需要準備歌曲檔案,就能在幾分鐘內完成音軌分離,省去到處找伴奏或人聲檔的麻煩。
核心功能與特色
以下是 UVR 的主要功能與特色:
-
支援多種模型(Multi‑model 支援)
提供多種訓練好的模型(例如 MDX‑Net、Demucs 等等)用於歌聲或音源分離。大部分模型是該專案核心開發者訓練的,但有少部分(例如 Demucs v3 與 v4 的四 stem 模型)非由他們本人製作。 -
圖形化操作介面(GUI)
使用者不需要自己寫程式,就可以透過易用的圖形介面操作。這降低了門檻,非常適合不是程式背景但想做歌聲去除的人。 -
跨平台支援
支援 Windows、macOS 與 Linux 系統。對於 macOS 的 M1(Apple Silicon)也有優化與支援。 -
GPU 加速與硬體需求
若你的電腦有 GPU(尤其是 NVIDIA 或支援 CUDA 的顯示卡),處理速度會快很多;對於較舊或資源較少的機器,可能要調整分段(segment)或視窗大小(window size)來降低資源消耗。 -
額外工具支援
-
FFmpeg:用來處理非 WAV 格式音檔的輸入/輸出。
-
Rubber Band:提供時間拉伸(time stretch)或音高變換(pitch shift)功能。
-
使用者的設定會被記憶,下次開啟程式就不用重設。
-
-
開源與授權
採 MIT 授權(MIT License),也鼓勵開發者引用模型與程式時要給予 UVR 及其開發者適當的信用。
安裝與使用方式概要
以下是安裝與實際使用中會注意到的一些細節:
-
下載與安裝
Windows 用戶通常可以下載專門的安裝包或執行安裝程序;macOS 可以下載 DMG 或者從 GitHub 抽出 repo 自行安裝。 Linux 則可透過安裝 Python + 套件 + 外部工具(FFmpeg、Rubber Band)手動架構。 -
硬體要求
如果僅用 CPU 處理,速度會比較慢。若有 GPU(特別是 NVIDIA,支援 CUDA)則效果與速度提升非常明顯。記憶體 (RAM) 的需求也隨模型大小與檔案長度增長而增加。我的測試中,用較大的模型對於 44.1 kHz、幾分鐘或更長的音檔時,若不分段處理會耗時並且有可能耗盡記憶體。 -
模型選擇與音質
不同模型在「保留背景音質」與「完全去掉人聲」之間的妥協不一樣。有些模型對人聲抑制非常好,但可能伴奏失真或殘留些微人聲;有些模型保留音質好,但人聲去除得不完全。使用者可以依用途(卡拉OK vs 創作 vs 傳播等)來試不同模型。 -
使用者介面
GUI 本身操作直觀,有設定可以調整輸出格式、是否時間拉伸/音高變換、segment/window size 等等。這些設定若調得當,可以減少處理時間或避免記憶體爆掉的情況。操作之後如果有錯誤/崩潰,Error Log 通常會提供不少線索。 -
穩定性與錯誤
部分系統(尤其是 macOS 最新版本)曾出現滑鼠點擊事件不回應等 bug;專案有持續更新這些問題。也要注意外部依賴(FFmpeg、Rubber Band)版本是否適合。
適合對象與應用場景
-
想做卡拉 OK版本自製歌伴奏但不想買伴奏檔的人。
-
音樂製作人或影音創作者需要去人聲再加上自己的人聲/混音。
-
教學用途,例如音樂課、歌唱教學等,需要聽純歌伴或純伴奏。
-
想研究音訊處理(source separation)技術、測試不同模型效果的愛好者。
如果你也有去除音樂中人聲的需求,可以試著使用這個開源的工具來看看成效。