標籤: 網路爬蟲 頁1
網路爬蟲相關的文章,目前共收錄 5 篇內容。

網路資源
Cloudflare Crawl Endpoint:用 API 快速抓取網站內容的雲端爬蟲服務
Cloudflare Crawl Endpoint 是 Cloudflare Browser Rendering API 的功能之一,讓開發者透過 REST API 抓取網站內容並支援 JavaScript 渲染。本文介紹其核心概念、功能特色與應用場景,了解如何用雲端方式建立網站爬蟲系統。

網路資源
Magnitude:以「視覺為先」的開源瀏覽器自動化與測試框架
Magnitude 是開源 AI 瀏覽器自動化平台,支援自然語言操作、資料擷取與 UI 測試,適用無 API 網頁流程,專為開發者與資料工程師打造。

網路資源
Scraperr:免寫程式、自架網站的開源爬蟲服務
Scraperr 是 self-hosted 圖形化網頁爬蟲工具,免寫程式碼即可透過 XPath 擷取資料、管理任務,支援媒體下載與結果匯出。
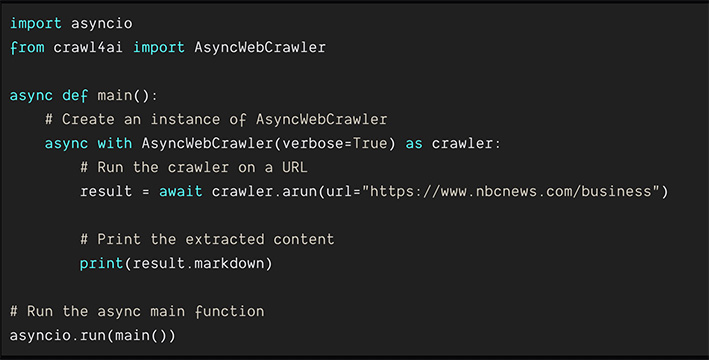
網路資源
Crawl4AI:專為人工智慧訓練設計的開源網頁資料爬蟲工具
Crawl4AI 是由 unclecode 開發的開源專案,專為 AI 和 ML 訓練數據準備設計,支援自動化網頁爬取、資料清理與標註,並具備反爬蟲技術應對,適合各類 AI 應用。

網路資源
Browse AI:無需程式碼的網站資料抓取和監控工具
Browse AI 是一款強大的工具,讓使用者無需編寫程式碼即可從任何網站提取和監控資料。透過簡單的訓練機器人過程,使用者能夠在短短兩分鐘內設置自動化任務,並以電子表格形式接收資料。無論是定期監控網站變更還是批次運行多達 50,000 個機器人,Browse AI 都能滿足各種需求。